大战略perfect40(4大战略)

大战略perfect40
指挥官担任着游戏的重要角色,玩家在不同的地图可以选择不同的作战指挥官。每个指挥官给上阵部队加成的属性都各不一样,其军衔等级越高属性加成越多。选择并调整指挥官策略才是胜利法则,运用指挥官的技能搭配,征服你的将士们!快去驰骋战场,感受精英部队带来的作战*吧
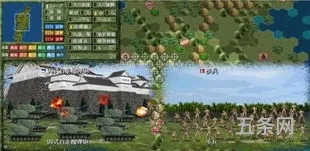
大战略是一种非常受欢迎的战棋类游戏,它以全球战争为背景,玩家可以通过制定战略、指挥军队来争夺领土和资源。这款游戏具有丰富多样的游戏模式和战役,让玩家可以体验到不同的历史时期和战争风格。
起源于早期的P36战斗机,后来随着艾莉森V-1710V-12型液体冷却发动机的研制成功,美国*要求对P36进行改造,于是一种搭载全新发动机的P40战斗机诞生了。并在当年莱特菲尔德举行的*追击比赛中,P-40获得了胜利。其在低空与中空高度展现出了高度的灵活性。
相比国内外追求单一最优的基座大模型厂商,虽然它们在技术研究上也取得不错突破,在单一模态、部分任务上能实现最优,但整体能力仍然偏弱,距离GPT-4有很大差距。
据AI科技评论独家对话Zoom团队,过去半年,他们基于联邦大模型在落地上取得了飞速进步,主要体现在三方面:
4大战略
在语言支持方面,早期的AI大模型、包括现在的大部分模型主要以英语数据为主进行预训练,Zoom则增加了翻译模型,扩展了多语言能力,目前已经可以支持除英语以外的32种语言。
与其他AI应用改造不同的是,Zoom采用了联合AI的方法,其也是Zoom创新的基石。据悉,目前Zoom已经接入了多个模型,其中包括Zoom自研的LLM、第三方模型GPT-3.5和GPT-4,以及AnthropicAI的Claude2等大模型。
与大多数侧重应用的厂商一样,Zoom对大模型的诉求也主要体现在性价比上——用最低廉的价格实现最强的模型能力,从而为用户提供最优质的服务,提高用户满意度。例如,提高视频会议的沟通效率,增强会议的自动文本总结功能,自动生成会议草稿与会议问答等。为此,Zoom选择联邦大模型的路线更具优势。
Zoom能根据具体的场景选择最适合的且成本最低的LLM。根据Z-Scorer评估初始任务的完成质量评估,Zoom会视情况调用更高级别的LLM来根据初始LLM所取得的成果增强任务的完成。
究其原因,是因为大部分的厂商在同时兼顾效果与成本上分身乏术,要么没有足够的财力,要么没有足够的能力。而由于对自研文化的极致推崇,原本优势集中在应用场景上的玩家也更倾向于通过自己的力量将模型做大做强,缺少向外学习、取长补短的意识。
完美大战略4中文补丁
大模型在行业落地时,最为严峻的挑战聚焦在性能、反应速度以及成本三方面,但Zoom团队提出的联邦大模型方法较好地解决了这些挑战。据AI科技评论观察,目前国内还没有企业能将超过四个、甚至更多的大模型联邦整合起来。
在算力层面,联邦大模型用小于10%的计算资源可以达到GPT-4在Zoom应用场景中99%的性能、并大大超越GPT-4的反应速度。
这背后主要还是技术的考验,即根据具体的应用场景应该选哪些模型。在这基础上,如何进行融合,也有很强的技术壁垒。



最新文章
-

环保棕垫和椰棕床垫哪个好(环保椰棕床垫和普通椰棕的分别)
2024-05-30 -

多年父子成兄弟的话题是什么(亲兄弟之间的感情)
2024-05-30 -

符文密码下册(符文密码小说免费)
2024-05-30 -
怎么在word方框里打钩子(word文档√怎么打)
2024-05-30 -

关于感恩父母的作文400字左右(感恩成长路上有良师相伴)
2024-05-30 -

张慧君简历(张慧君的个人资料)
2024-05-30 -

陈冲现在的情况(57岁陈冲一家近照)
2024-05-30 -

关于感恩母亲的作文题目(感恩妈妈的题目建议用什么)
2024-05-30
热门文章
-

芽菜种植方法和技术设备(100平方芽苗菜利润)
2024-05-23 -

慈善祝词(给做公益慈善的祝福)
2024-05-23 -
电脑指法打字教学(键盘打字指法视频教程)
2024-05-25 -

刘梓晨是谁呀(你知道刘梓晨吗)
2024-05-26 -

"四级满分多少,及格多少(四级英语满分和及格分)
2024-05-23 -

肖申克救赎的名言名句(肖申克最经典十句话)
2024-05-23 -
百度文库如何查看财富值(百度文库收益)
2024-05-24 -

社区活动有哪些项目(社区公益服务项目)
2024-05-24
有话要说...