决策树算法原理(简单说明决策树原理)

决策树算法原理
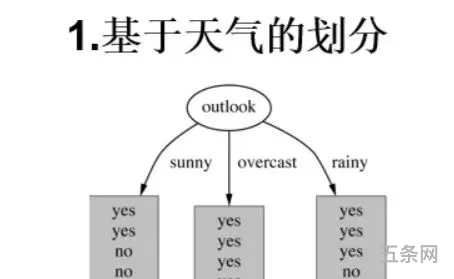
最早的决策树算法是由Hunt等人于1966年提出,Hunt算法是许多决策树算法的基础,包括ID3、C4.5和CART等。
增益率准则就可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
速度快:计算量相对较小,且容易转化成分类规则。只要沿着树根向下一直走到叶,沿途的分裂条件就能够唯一确定一条分类的谓词。准确性高:挖掘出的分类规则准确性高,便于理解,决策树可以清晰的显示哪些字段比较重要。非参数学习,不需要设置参数。
越小,则数据集的纯度越高。CART生成的是二叉树,计算量相对来说不是很大,可以处理连续和离散变量,能够对缺失值进行处理。
来进行划分所获得的“纯度提升”越大。因此,我们可使用信息增益来进行决策树的划分属性选择。ID3决策树学习算法就是以信息增益为准则来选择划分属性的。
简单说明决策树原理
本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅!
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树很容易过拟合,很多时候即使进行后剪枝也无法避免过拟合的问题,因此可以通过设置树深或者叶节点中的样本个数来进行预剪枝控制;决策树属于样本敏感型,即使样本发生一点点改动,也会导致整个树结构的变化,可以通过集成算法来解决;
:在生成决策树之后再剪枝。通常会从决策树的叶节点开始,逐层向上对每个节点进行评估。如果剪掉该节点,带来的验证集中准确性差别不大或有明显提升,则可以对它进行剪枝,用叶子节点来代填该节点。
:典型的算法有ID3和C4.5,它们生成决策树过程相似,ID3是采用信息增益作为特征选择度量,而C4.5采用信息增益比率。
决策树算法的步骤和公式
(DecisionTree)又称为判定树,是数据挖掘技术中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
:表示事物不确定性的度量标准,可以根据数学中的概率计算,出现的概率就大,出现的机会就多,不确定性就小(信息熵小)。
叶结点对应于决策结果,其他每个结点对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定的测试序列。决策树学习的目的是产生一棵泛化能力强,即处理未见示例强的决策树。
:在决策树构造时就进行剪枝。在决策树构造过程中,对节点进行评估,如果对其划分并不能再验证集中提高准确性,那么该节点就不要继续王下划分。这时就会把当前节点作为叶节点。
关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧!
相关文章





最新文章
-

环保棕垫和椰棕床垫哪个好(环保椰棕床垫和普通椰棕的分别)
2024-05-30 -

多年父子成兄弟的话题是什么(亲兄弟之间的感情)
2024-05-30 -

符文密码下册(符文密码小说免费)
2024-05-30 -
怎么在word方框里打钩子(word文档√怎么打)
2024-05-30 -

关于感恩父母的作文400字左右(感恩成长路上有良师相伴)
2024-05-30 -

张慧君简历(张慧君的个人资料)
2024-05-30 -

陈冲现在的情况(57岁陈冲一家近照)
2024-05-30 -

关于感恩母亲的作文题目(感恩妈妈的题目建议用什么)
2024-05-30
热门文章
-

芽菜种植方法和技术设备(100平方芽苗菜利润)
2024-05-23 -

慈善祝词(给做公益慈善的祝福)
2024-05-23 -
电脑指法打字教学(键盘打字指法视频教程)
2024-05-25 -

刘梓晨是谁呀(你知道刘梓晨吗)
2024-05-26 -

"四级满分多少,及格多少(四级英语满分和及格分)
2024-05-23 -

肖申克救赎的名言名句(肖申克最经典十句话)
2024-05-23 -
百度文库如何查看财富值(百度文库收益)
2024-05-24 -

社区活动有哪些项目(社区公益服务项目)
2024-05-24
有话要说...